
The popularity of data extraction has rocked the restaurant business. Restaurant operators collect menu information from competitor establishments to develop unique menus and special offers that distinguish them. A thorough understanding of how much different products cost in the market can aid in creating a competitive pricing strategy. Prepare to discover countless potential using web-scraped restaurant data.
By using restaurant data scraping, you may obtain a transparent, valuable database of restaurants that contains various types of data, including addresses, menus, reviews, mentions, and much more. Without the technological hassle, all of this.
You can get structured restaurant data from one or more websites on the internet using our high-quality restaurant data feeds, allowing you to build the ideal restaurant database. We can expand as your needs do.
Foodspark Data Extraction supports a wide range of metadata types. Our QA procedure has been refined over more than ten years to provide high-quality restaurant online data.
This application will collect information about restaurants' names, reviews, and Google reviews, as well as their locations, phone numbers, and hours of operation. To make the data easier to read, we will convert it to Excel format.
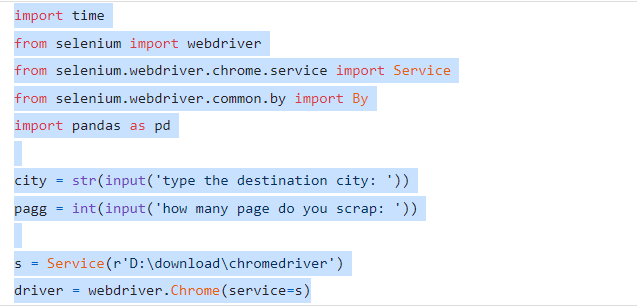
We must first install all of the necessary packages, including Selenium and Webdriver for data scraping, and then Pandas and openpyxl for creating an Excel file with the data we previously collected.
The other installed packages are then imported, together with the package time, which fixes issues where an item has yet to appear. Then, two input-containing variables are created. The first input specifies the destination city as a string, and the second is a variable with an integer input specifying the number of pages we will need.
The service package derivative of the selenium package is then contained in a new variable created next. We insert the web driver software path we obtained into this package. The web driver package we have installed is then stored in a variable we create. We utilize Chrome and input the s variable that we set previously as a place for our web driver file so that the web driver can read it because I use Chrome as a Selenium browser.
Our selenium application is then executed. The restaurant URL that we modified is then navigated to include the city variable in the URL. Next, we pause our program using the time package's sleep function feature. If we can locate the click button on the image below using the XPath that is searched using the discover element feature on the web driver and ends with the click-to-press button, we halt it for 7 seconds so that the web opens perfectly. The final step is to construct a data variable with an empty list that will hold the scraping results and be used to extract them into an Excel file.
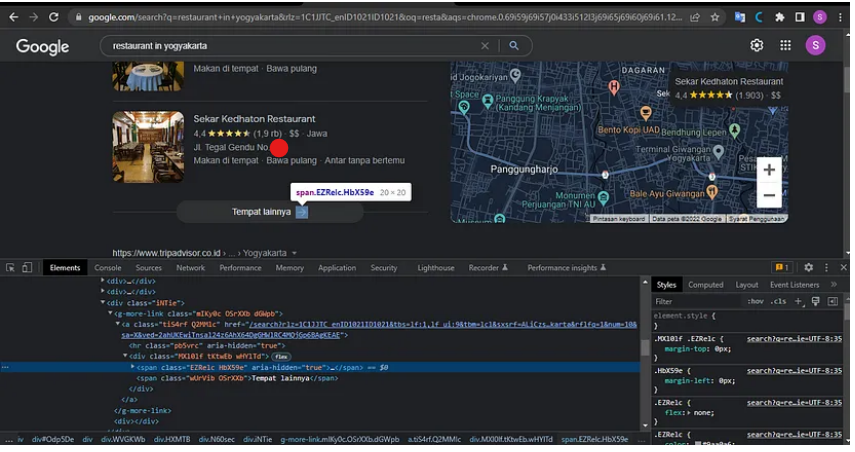
Coding in the Second stage
|
river.maximize_window()
|
|
driver.get(f'https://www.google.com/search?q=restaurant+in+{city}')
|
|
time.sleep(7)
|
|
driver.find_element(by=By.XPATH, value='//*[@id="Odp5De"]/div/div/div[2]/div[1]/div[4]/g-more-link/a/div/span[1]').click()
|
|
|
data = []
|
It's time to begin scraping the information we require now that we are on Google Maps. If we wish to scrape restaurant and food data
Links to an external site. on more than one page, we first establish a for loop with a range of zero to the page variable, and this looping function creates a scraping loop on the following page. After that, we pause our software for 7 seconds to ensure the site opens flawlessly. Following that, we will scrape all the required data, as shown below.
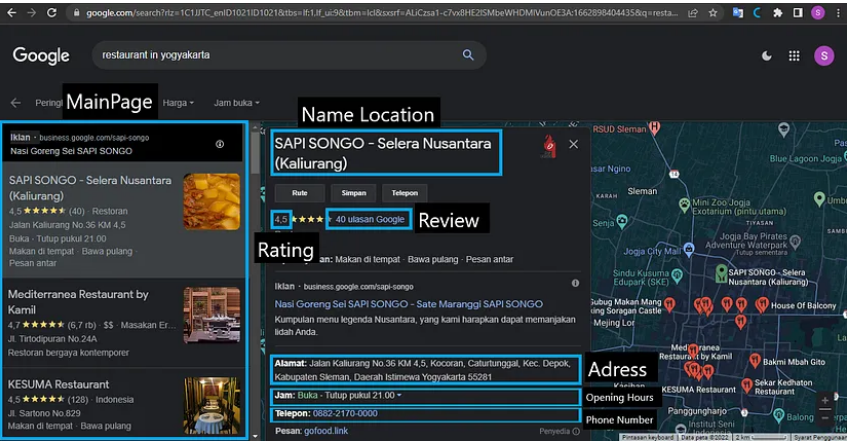
As seen in the above image, the first step is to use the search for XPath elements to click on the main page. Next, we'll design another loop that will function to retrieve the data we require. When we click the home page in this loop, the software will pause for 7 seconds while we wait for the web to open. Next, we gather information about the restaurant's name, rating, reviews, and location. The next step is to fix the issue if a restaurant doesn't have a phone number using the data on phone numbers. Finally, we'll use information about restaurant opening times.
We will start by using try unless the same as before because the data gathering procedure for this opening differs from previous ones. After all, the data format is different. In the try function, we will click the clock to open it and collect all the data. If it doesn't exist, we take the data differently and enter the value "no opening hours" in the exception part of the try function. This is the third level of our code.
|
for a in range(0, pagg):
|
|
time.sleep(7)
|
|
mainpage = driver.find_elements(by=By.XPATH, value='//div[@jsname="GZq3Ke"]')
|
|
|
for start in mainpage:
|
|
start.find_element(by=By.CLASS_NAME, value='rllt__details').click()
|
|
|
# waiting for opened js
|
|
time.sleep(7)
|
|
|
# start scrap
|
|
title = driver.find_element(by=By.CLASS_NAME, value='SPZz6b').find_element(by=By.TAG_NAME, value='h2').find_element(by=By.TAG_NAME, value='span').text
|
|
rating = driver.find_element(by=By.CLASS_NAME, value='Aq14fc').text
|
|
review = driver.find_element(by=By.CLASS_NAME, value='hqzQac').find_element(by=By.XPATH, value='//*[@id="akp_tsuid_9"]/div/div[1]/div/div/block-component/div/div[1]/div/div/div/div[1]/div/div/div[1]/div/div[2]/div[1]/div/div/span[3]/span/a/span').text
|
|
location = driver.find_element(by=By.CLASS_NAME, value='LrzXr').text
|
|
|
# scrap phone number
|
|
try:
|
|
numm = driver.find_element(by=By.XPATH, value='//span[(@class="LrzXr zdqRlf kno-fv")]').text
|
|
except Exception:
|
|
numm = 'no phone number'
|
|
|
# scrap for opening hours
|
|
try:
|
|
driver.find_element(by=By.CLASS_NAME, value='IDu36').click()
|
|
opening = driver.find_element(by=By.CLASS_NAME, value='WgFkxc').text
|
|
if opening == '':
|
|
time.sleep(3)
|
|
opening = driver.find_element(by=By.XPATH, value='//table[(@class="WgFkxc CLtZU")]').text
|
|
driver.find_element(by=By.XPATH, value='//*[@id="gsr"]/div[12]/g-lightbox/div/div[2]/div[2]').click()
|
|
except Exception:
|
|
opening = 'no opening hours'
|
We've reached the end of the process now. In other words, we construct a variable with a data dictionary type and add the last variable to the data variable with the list data type we previously made. This variable will contain the data from the scraping results. Additionally, we can print the data we collected to determine whether it is appropriate or not. Then, using try-except, we construct a function in the first loop that clicks the next page button if one is present.
Finally, we will export the data to an Excel file using Panda's package after scraping. The file will be named based on how many pages were scraped for the variable using the previously defined page. And here is the final code we have.
|
dat = {
|
|
'Name': title,
|
|
'Rating': rating,
|
|
'Review': review,
|
|
'location': location,
|
|
'Phone Number': numm,
|
|
'Opening Hours': opening
|
|
}
|
|
data.append(dat)
|
|
|
# test result
|
|
print(f'{title}, rating = {rating}, {review}, location: {location}, phone: {numm}, operational hours: {opening}')
|
|
|
# click next page
|
|
try:
|
|
driver.find_element(by=By.XPATH, value='//*[@id="pnnext"]/span[2]').click()
|
|
except Exception:
|
|
break
|
|
|
# create data excle
|
|
df = pd.DataFrame(data)
|
|
df.to_excel(f'result from {pagg} page.xlsx', index=False)
|
|
|
driver.close()
|
The software then operates to our preferences, considering all the information we provide, including restaurant names, addresses, phone numbers, ratings, and reviews.
Conclusion
With the help of our enterprise-grade, well-managed, and end-to-end solutions, you may get all the information you require from restaurants in every country on earth. If necessary, any form of unique restrictions, such as filters for specific types of eateries, might also be put into practice.
At Foodspark
Links to an external site., we provide a real-time, lower latency food and restaurant data scraping service. The infrastructure setup and maintenance are taken care of by our well-managed food data scraping services. Our comprehensive cloud-based solutions take into account any integration needs that clients may have. As a result, we provide data using REST APIs, S3, or DropBox in a variety of formats, including JSON, CSV, and XML.

 icons at the top right corner of the subsection.
icons at the top right corner of the subsection.